A curious case of O(N^2) behavior which should be O(N) · GitHub
Recently I have become interested in Blender 3D, partly inspired by Infinigan project.
one day i met Trussim. I was so impressed by its rendering quality that I browsed its blog and saw this. Wow, Tellusim really blows away others; others include Unreal, Unity, Omniverse and mixer. Wait, is Blender really that slow at importing USD scenes?
Since Blender is open source, why not try to figure out what’s going on? here we go.
I cloned the latest version of Blender 4.0.0.Alpha and installed all dependencies. Building is a simple matter. I’m using Windows 10 and miss perf on Linux. But VS2022 Community Edition does include analysis tools: Microsoft (R) VS Standard Collector. Enter the directory where Blender.exe is located and execute:
VSDiagnostics start 1 /launch:blender.exe /loadConfig:"C:\Program Files\Microsoft Visual Studio\2022\Community\Team Tools\DiagnosticsHub\Collector\AgentConfigs\CpuUsageBase.json"
now in blenderimport limits_32.usdc Unzip from here test file. This will take a while, on my machine it is approx. 30 Second. After the import is complete, execute
VSDiagnostics.exe stop 1 /output:"usd_import1"
document usd_import1.diagsession There will be an analysis message and you can check it in VS by opening it.
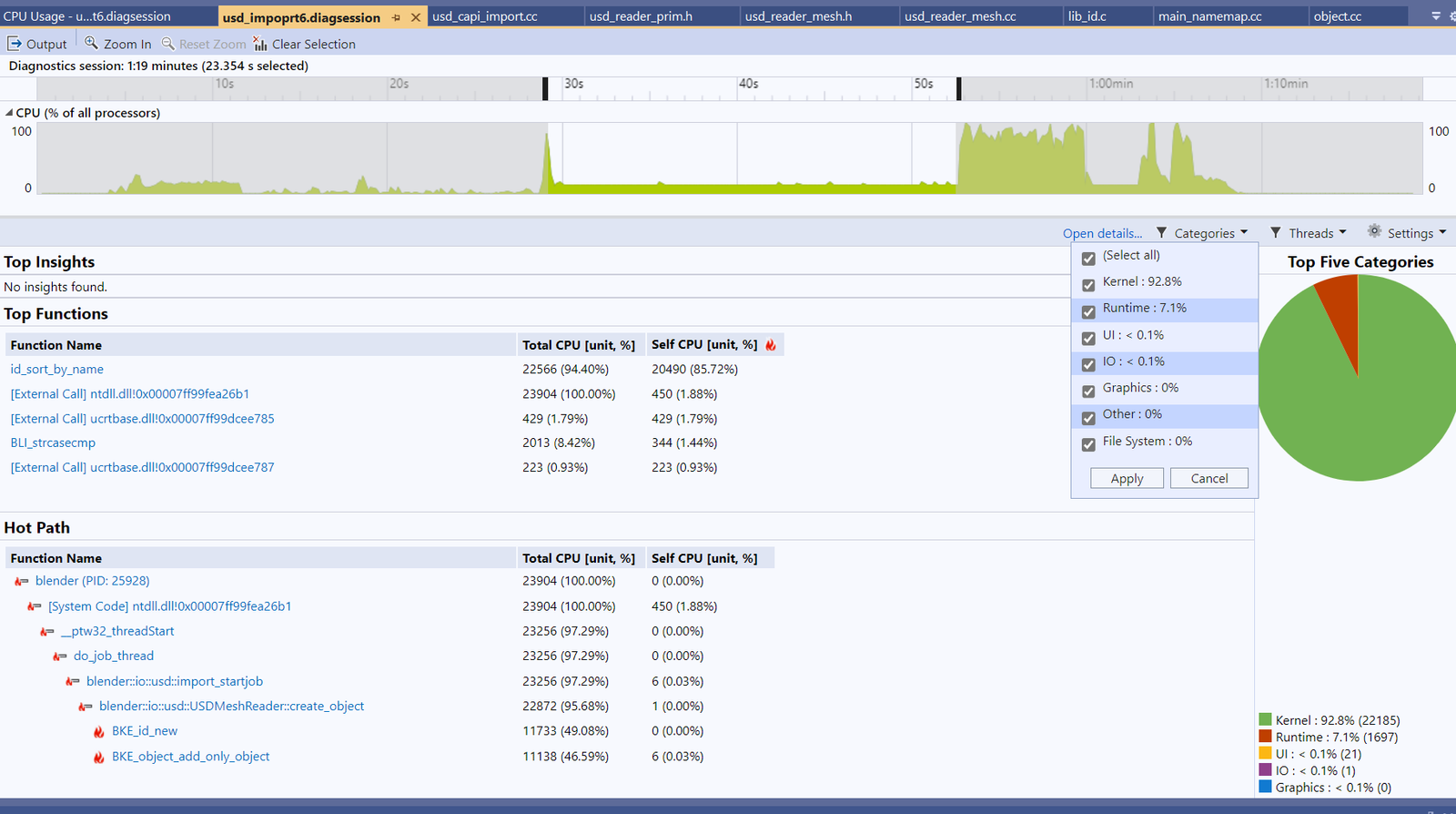
This is what it looks like on my system. Flame graphs are also available if required.
Now, it should be clear that the majority of the time (28 seconds to 53 seconds on the timeline) of importing this particular USD file was spent id_sort_by_name. but why? What does it do? id_sort_by_name Do? It took me a while to figure it out with the help of code comments. Blender will create many objects (of type ID) when importing a scene or when the user creates primitives. Internally, Blender maintains a doubly linked list of these IDs. The list is sorted by ID unique Named in alphabetical order. Each time a new object (ID) is created, id_sort_by_name The call inserts the newly created ID into the list. Because the list is sorted and Blender assumes that all objects created later have higher extensions (i.e. are alphabetically larger), the search starts at the end and works backwards. Well, that sounds reasonable, since each insertion is likely to happen at the end of the list, with a time complexity of O(1), and the entire process is O(N), where N is the number of new IDs. But how does profiling tell a different story?
All usd files with performance issues have one thing in common: they have an entity that is shared by many objects. Blender’s USD import utility creates a new object for each reference. Since they all have the same name, another program assigns a number to the object with the registered name to make it unique. The problem is that allocation is based on a counter starting from 1. basename.12313 Alphabetically less than basename.9999 Although the latter came later than the former. Therefore, linked list search requires many more steps to find the insertion place. basename.12313. In effect, the O(N) process becomes O(N^2). We all know how bad O(N^2) is, right?
By now the solution should be clear: change the naming. Instead of changing the universal name decorating function used by Blender, I made some modifications directly to the USD import module: I counted the total number of objects in the USD file and got the width in total digits, then assigned a unique base name to each New name and format basename_00XXX where XXX is their index and padded with 0s so they all have the same number of bits. This way ID_00999 Will be closer to the head of the list, not the tail.
It turns out that the above solution is not ideal. It can’t handle importing the same USD archive over and over again, or multiple archives with the same base name (which quickly gets back to O(N^2)). Given that the process of assigning extension numbers uses a counter for each base name, I came up with another solution. exist id_sort_by_nameinstead of comparing the whole name (basename + number), I split it into two parts: first comparing the basename, and if the basenames are the same, then comparing the number. This fix provides similar performance as before (see below) while allowing any number of files to be imported.
After the above temporary fix, loading limits_32.usdc taken 8 seconds and a larger file limits_48.usdc taken 27 It took a whole few seconds before the fix 4 minutes and 40 seconds. good.
Now id_sort_by_name No longer a bottleneck. Other processes also stand out, e.g. USDMeshReader::read_object_data. For larger files, building the DAG becomes more time-consuming. There may be room to further reduce the time (maybe in another article) so that the entire Blender $import pipeline matches Omniverse 2023.1. However, I doubt Blender will be able to come close Tellusim.
Thank you for reading.
2024-12-21 19:34:07