A common approach I’ve often noticed in the past is that developers (myself included of course) use the same API for reading and writing in every case. What’s more, we often rely on the same source of data (e.g. MySQL/PostgreSQL) to handle both operations.
This means writing to and reading from the same column, often leading to difficulties in optimizing indexes on columns for large numbers of queries.
For example, we may find ourselves frequently adjusting indexes to accommodate new filters or improve query performance, and fields used with operators such as LIKE pose special challenges due to their impact on performance.
These changes often result in further adjustments to the backend, including modifications to the API to expose updated functionality, measured times due to additional JOINs, etc…
{kind=link}
To address the challenge of adding new filters and content to APIs, attempts have been made to optimize the process using tools and standards, e.g. the end of the world certainly, GraphQL.
These solutions are designed to simplify API query generation and reduce the manual work required to implement new filters and features, providing a more dynamic approach to handling data access, but they have a high learning curve.
{kind=link}
With the rise of CQRS (Command Query Responsibility Separation), a new approach began to emerge. This mentality encourages using separate sources for writing and reading. Writes can emit events, and reads can build views from these events in dedicated locations. Even though reads and writes are managed in the same database (but different tables), this separation brings significant benefits and of course gets rid of the second challenge – joins and search queries on the domain model, Because reading models is usually in the form of denormalized JSON.
{kind=link}
However, this raises another question. For reads, we have to scale writes, which means the only reason we have to scale the application instance from X to Y is for reads. This problem can be partially alleviated through cache. In the field of microservices, we can have dedicated microservices to read.
but…
Still, this is not an ideal solution for other architectural styles (such as modular monoliths), as this separation may not fit well with the system’s design philosophy. Another thing is that when an API goes down, the entire product goes down, remember that most products rely on more reads than writes, which can have an unnecessary impact on the business (besides the downtime of course API ;))
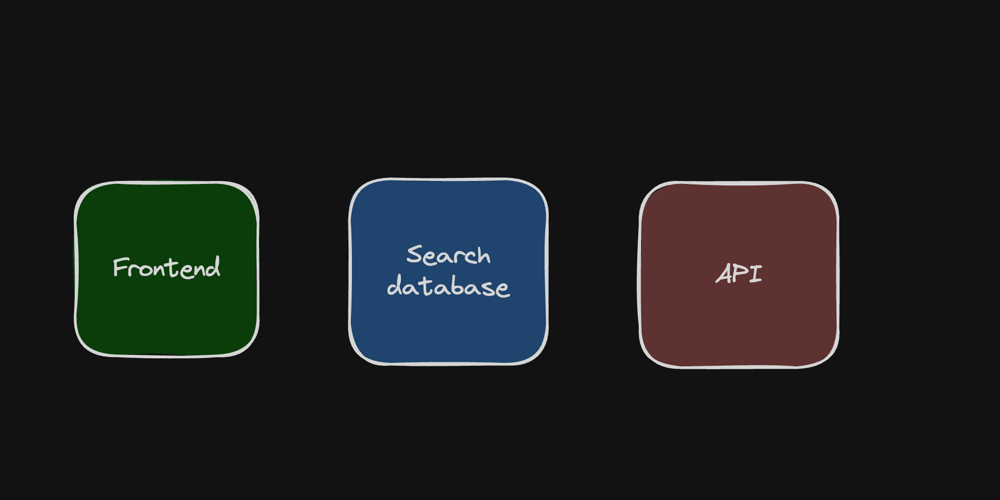
So what if we could directly interrogate these “views” (aka read models) without involving APIs and processing load? This is the solution like this beauty search, Application search Others function using a model called “valet key.” By using this pattern, the front-end can directly access the read-optimized model, reducing dependence on the back-end API. Of course, the front end still needs to “ask” the API for the valet key, but the front end can cache the key, so even if the API is closed, the front end can still communicate and display content.
{kind=link}
{kind=link}
This way we can focus on reading the database without worrying about handling the read traffic in the API. The “valet key” provided to the front-end through our API is protected and the front-end cannot change it. It includes predefined filters and indexes.
If the front end requires additional functionality, it can request them through the API, which can verify whether they are allowed. There are still fewer people calling.
Some advantages I see are:
- Reduce API load: Offload read traffic from the API, allowing it to focus on core operations.
- Scalability: Load database or search services are better optimized to handle high traffic, thereby reducing the need to scale the application backend.
- flexibility: SaaS or self-hosted options allow teams to choose the option that works best for their infrastructure.
- Safety: Pre-defined filters and indexes ensure that the front end can only access allowed data, minimizing risks. The API may invalidate the key.
- Developer efficiency: Reduce the need for constant API updates for new filters or search functionality.
- Improve performance: Direct access read-optimized models provide users with faster query responses.
However, there are always disadvantages:
- eventual consistency: Due to the nature of eventual consistency in the read model, data may appear after some time.
- Additional maintenance: Introducing additional elements that require monitoring and management.
- Pattern complexity: Patterns must be stored in code or in a public location because different teams from different contexts may need to populate the same document (e.g. employees with emails, but also with points and coupons available). Although not directly related to this pattern, it adds complexity.
- Cost of SaaS version or in-house maintenance
So this approach is not a panacea and comes with its own set of challenges, but if you can accept the shortcomings, small changes to the front end may not require the backend team’s involvement, streamlining the development process and improving overall agility, certainly Scalability should also be easier.