Eventual Consistency is Tricky – by Saurabh Dashora
What is eventual consistency?
The concept of eventual consistency refers to a system condition in which all parts of the system reach the same state, even though they may be temporarily inconsistent due to delays or failures.
Here’s the bad news:
You can’t escape eventual consistency in a decentralized system.
But there is good news:
As long as you follow good patterns to build your application, eventual consistency can help you scale your decentralized system.
Let’s look at some of the most useful patterns you can use:
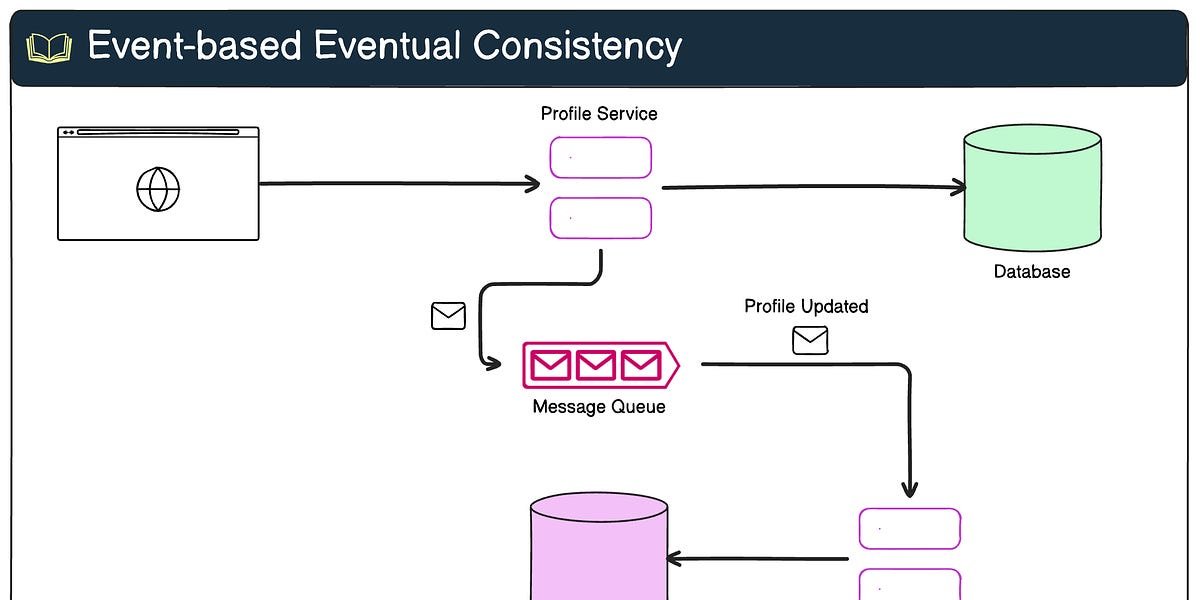
In this pattern, a service emits events when its state changes, and other services listen to these events to update their data.
These services do not communicate directly with each other, making them loosely coupled, which is great for scalability. However, this approach introduces a delay before all services reflect the latest state, leading to eventual consistency.
Here is an example:
Consider an e-commerce platform where users’ account profiles are managed by one service and the recommendation engine is handled by a separate service.
-
When a user updates preferences in their profile, an event like “Profile Updated” is emitted.
-
The recommendation service listens for this event and updates its database to reflect the new preferences.
-
There is a short delay between profile updates and updated recommendations, allowing for eventual consistency.
In this mode, a background program or job periodically synchronizes data between different databases.
Background jobs run as scheduled, checking for inconsistencies and making the data consistent. This approach often results in slower eventual consistency because synchronization only occurs at set intervals. However, user updates are efficient.
Here is an example:
Think of a social media application where user posts and user analytics data are stored in separate repositories.
-
A background sync job runs every few minutes to update the analytics database with new posts.
-
This allows the analytics service to eventually reflect all user posts, but users may see slight delays in analytics updates (e.g., post count increases) because synchronization only occurs after the background job runs.
The saga pattern breaks down distributed transactions into a series of local transactions, each handled by a single service.
After each service completes its local transaction, the next service starts. If something goes wrong, compensating transactions are triggered to roll back the changes so that the system is ultimately consistent.
Sagas are used for long-running complex business processes that need to ensure eventual consistency across multiple services.
Here is an example:
Think of a travel booking system where users can book vacation packages that include flights, hotels, and car rentals. Let us assume a strange requirement, if the rental car booking fails, the entire vacation plan needs to be cancelled.
-
Each of these is managed by a different service.
-
The booking process is divided into multiple steps (or transactions), handled by the corresponding services: booking a flight, then booking a hotel, and finally booking a car.
-
If a car rental fails, saga initiates compensatory actions, canceling flights and hotel reservations, thus maintaining eventual consistency throughout the system.
CQRS (Command Query Responsibility Separation) divides the system into two models: one for handling write operations (commands) and another for handling read operations (queries).
Each model is optimized for its specific task, and data is synchronized asynchronously between the two models, resulting in eventual consistency.
The write model processes changes immediately, while the read model eventually updates to reflect those changes.
Here is a possible example:
Consider a banking system where account balances are stored in a highly optimized database for read operations, allowing for fast access to balance queries.
-
Write operations (such as deposits or withdrawals) are handled by different repositories that are optimized for transaction integrity.
-
When a customer withdraws money, the write model is updated immediately, but the read model (the balance query system) takes a while to reflect this change, achieving eventual consistency between the two.
Each mode has its advantages and disadvantages.
-
event based: Suitable for building loosely coupled systems that prioritize scalability and flexibility, but consistency takes time due to asynchronous updates. This is more of a basic pattern.
-
Background sync: Best suited for systems where the data does not need to be immediately consistent and can be synchronized periodically, resulting in slower updates.
-
Based on Saga: Ideal for managing complex, long-term transactions with multiple services, ensuring consistency by compensating transactions.
-
Based on CQRS: Allows optimization of read and write operations, but consistency between the two models is achieved asynchronously.
So – have you seen other eventual consistency patterns?
Here are some interesting articles I’ve read recently:
That’s it for today! ☀️
Like this newsletter?
Share it with your friends and colleagues.
Watch another version later – Saurabh
2024-12-10 10:25:30