Meta launches Llama 3.3, shrinking powerful 405B open model
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. learn more
Meta’s VP of Generative Artificial Intelligence Ahmad Al-Dahle competes with Social Network X today Announcement of Camel 3.3, The latest open source multilingual Large Language Model (LLM) from the parent company of Facebook, Instagram, WhatsApp and Quest VR.
As he writes: “Llama 3.3 improves core performance at a significantly reduced cost, making it more accessible to the entire open source community.”
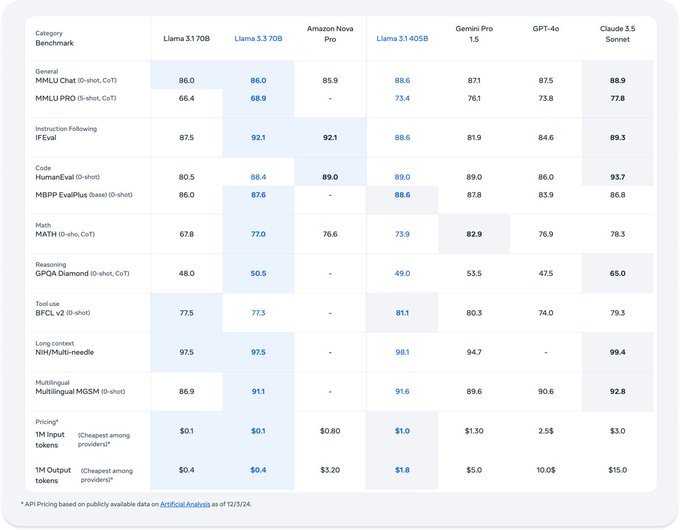
With 70 billion parameters (or settings that control model behavior), Llama 3.3 provides results comparable to Meta 405B parametric model from Llama 3.1 Starting over the summer, but at a fraction of the cost and computational overhead – the GPU capacity required to run models in inference.
It’s designed to offer top performance and accessibility in a smaller package than the previous base model.
Meta’s Llama 3.3 is available in Llama 3.3 Community Licensewhich grants a non-exclusive, royalty-free license to use, copy, distribute and modify the model and its output. Developers integrating Llama 3.3 into products or services must include appropriate attribution, such as “Built with Llama,” and adhere to an acceptable use policy that prohibits activities such as generating harmful content, violating laws, or facilitating cyberattacks. While licenses are generally free, organizations with more than 700 million monthly active users must obtain a commercial license directly from Meta.
The Meta team’s AI statement underscores this vision: “Llama 3.3 delivers leading performance and quality in text-based use cases at a fraction of the cost of inference.”
How much savings are we really talking about? Some rough math:
According to official data, Llama 3.1-405B requires 243 GB to 1944 GB of GPU memory Bottom blog (for Open source and cross-cloud bottom layer). Meanwhile, the older Llama 2-70B requires 42 to 168 GB of GPU memory, according to the company. same blogalthough some people have Claimed to be as low as 4 GBor as Exo Labs shows off several Mac computers equipped with M4 chips And there is no independent GPU.
So if the GPU savings of the low-parameter model still hold in this case, those looking to deploy Meta’s most powerful open-source Llama model can expect to save up to nearly 1940 GB of GPU memory, or potentially achieve a 24x reduction standard GPU load 80GB Nvidia H100 GPU.
estimate $25,000 per H100 GPUwhich could potentially save up to $600,000 in upfront GPU costs, not to mention ongoing power costs.
High-performance model in a compact form factor
according to Meta-artificial intelligence on Xthe Llama 3.3 model performs significantly better than the similarly sized Llama 3.1-70B and How Amazon’s new Nova Pro models perform on multiple benchmarks Examples include multilingual dialogue, reasoning, and other high-order natural language processing (NLP) tasks (Nova outperforms it on the HumanEval encoding task).

According to information provided by Meta in a “model card” posted on its website, Llama 3.3 has been pre-trained on 15 trillion tokens from “publicly available” data and on more than 25 million synthetically generated examples. fine-tuned.
The model was developed using 39.3 million GPU hours on H100-80GB hardware, highlighting Meta’s commitment to energy efficiency and sustainability.
Llama 3.3 leads the multilingual reasoning task with 91.1% accuracy on MGSM, demonstrating its support for languages such as German, French, Italian, Hindi, Portuguese, Spanish and Thai in addition to English effectiveness.
Cost effective and environmentally conscious
Llama 3.3 is specifically optimized for cost-effective inference, with token generation costs as low as $0.01 per million tokens.
This makes the model highly competitive against industry peers such as GPT-4 and Claude 3.5, and more affordable for developers looking to deploy complex AI solutions.
Meta also emphasized the environmental responsibility of this release. Although the training process is very intensive, the company uses renewable energy to offset greenhouse gas emissions, achieving net-zero emissions during the training phase. Total location-based emissions are 11,390 tonnes of CO2e, but Meta’s renewable energy plans ensure sustainability.
Advanced features and deployment options
This model introduces several enhancements, including a longer 128k token context window (~400 pages of book text compared to GPT-4o), making it suitable for long-form content generation and other advanced use cases.
Its architecture incorporates Grouped Query Attention (GQA) to improve scalability and performance during inference.
Llama 3.3 is designed to satisfy user preferences for safety and practicality, using reinforcement learning with human feedback (RLHF) and supervised fine-tuning (SFT). This consistency ensures strong rejection of inappropriate prompts and assistant-like behavior optimized for real-world applications.
Llama 3.3 is now available for download Yuan, Face hugging, GitHuband other platforms that provide integration options for researchers and developers. Meta also provides resources such as Llama Guard 3 and Prompt Guard to help users deploy models safely and responsibly.
2024-12-06 18:24:35