Slow Deployment Causes Meetings – by Kent Beck
First published 2016.
“I can’t get any code out of all these meetings.” What if this long-time engineer complains about backwards causation? Adding and removing organization overhead is relatively easy compared to increasing an organization’s ability to deploy code. What if meetings and reviews were an adaptive response by organizations to avoid deployment overload?
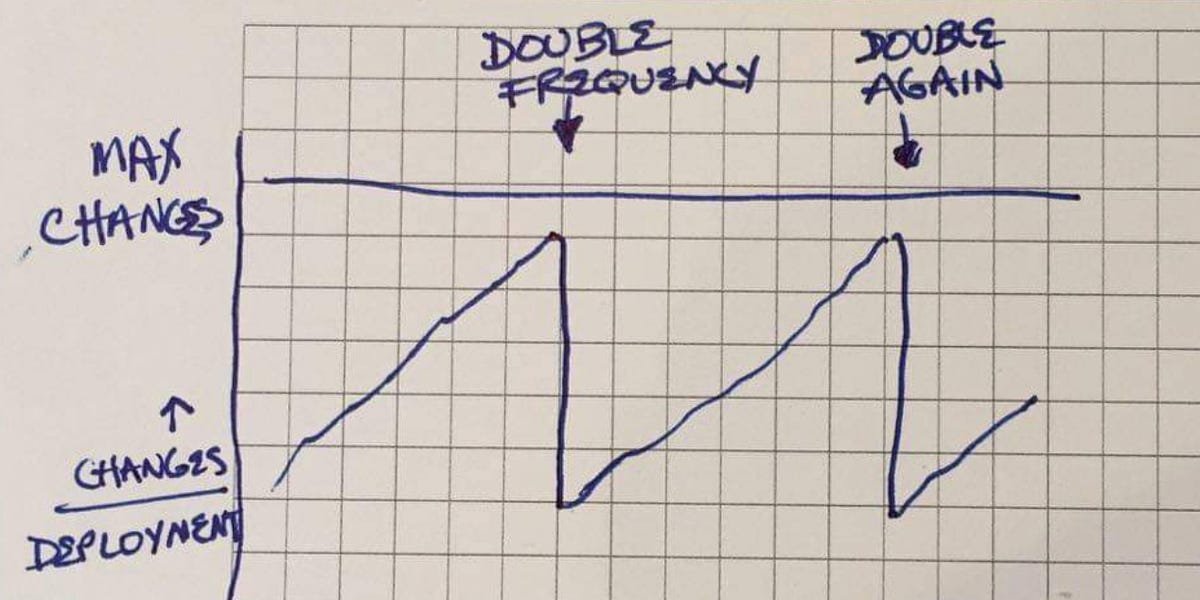
Chuck Rossi [ed: legendary release manager at early-to-middle Facebook] Observe that Facebook seems to be able to handle a fixed number of changes in a single deployment. If we want more change, we need more deployment. This has resulted in a steady increase in deployment speed over the past five years, with deployment cycles for PHP code increasing from weekly to three deployments per day, and for mobile applications from six weeks to four weeks to two weeks. This improvement was primarily driven by the Release Engineering team (I’m a fan, can you tell?)
Yesterday, as I was drifting off to sleep, I looked at the zigzag Changes Per Deployment chart and it dawned on me that maybe our organizational overhead was all wrong. “Changes per deployment” seems to be an inflexible metric. Improvements are possible, but only with significant effort over time. What happens when the number of changes produced exceeds the current threshold? Changes will not change with each deployment. The number of changes must be reduced.
how? Ultimately it kills enthusiasm and initiative by adding overhead costs – meetings, reviews, handovers, overhead. No one will admit to doing this on purpose, but perhaps the organization’s emergency response is locally optimal—changing the things that are easiest to change, thereby relieving stress.
Increasing overhead triggers a positive feedback loop: less work done -> more stress -> more errors -> fewer changes per deployment -> more overhead -> less work done. Efforts to reduce overhead alone can increase stress and increase overhead.
If you want to make more changes, you’ll need to extend the far end of the hose to increase deployment capabilities. You can do this the hard way by reducing deployment cycles and dealing with the chaos that comes with it, or by increasing the number of changes per deployment (better testing, better monitoring, better between elements isolation, better social connections online) to achieve this. But don’t try to reduce your expenses. This will inevitably lead to a series of meetings about how to reduce meetings. But at least this will stop you from trying to send too much code.
This article is an example of Thinkie reverse causation. This is one of the most interesting Thinkies to deploy because their idea seems so wrong at first.
2024-12-22 03:12:23