Synthetic Data Generation with LLMs | Towards Data Science
The popularity of rags
Over the past two years, working with financial firms, I personally observed how they identify and set priorities in generative cases of AI, balancing the complexity with potential value.
Searched generation (RAG) is often distinguished as the fundamental ability in many decisions controlled by LLM, which causes a balance between ease of implementation and real exposure. Combining Retriever that the surface of the relevant documents with LLM what synthesizes the answers, rag Opties access to knowledgeMaking it invaluable for applications such as customer support, research and management of internal knowledge.
The definition of clear evaluation criteria is the key to ensuring that LLM solutions meet performance standards, as well as the development of testing (TDD) provides reliability in traditional software. When engaged from the principles of TDD, focused on the approaches of the approaches establishes measurable criteria to verify and improve the work processes of AIThis field becomes especially important for LLMS, where the complexity of open answers requires a consistent and thoughtful assessment to achieve reliable results.
For RAG applications, a typical assessment set includes representative-and-outs input and output, which correspond to the alleged use of use. For example, in the Chat -Bott applications, this may include pairs of questions and answers that reflect user requests. In other contexts, such as extracting and summing up the corresponding text, the assessment set may include starting documents along with the expected resume or the extracted key points. These couples are often generated from the subuptionality of documents, such as those that are most visible or often available, which provides an assessment of the most relevant content.
Key problems
Creating assessment data sets for Rag Systems traditionally faces two main problems.
- The process often relied on experts on issues (SMEs) to manually view documents and generate pairs of questions and answers, making it in time, inconsistent and expensiveField
- Restrictions that prevent the processing of visual elements in documents, such as tables or diagrams, since they are limited by text processing. Standard OCR tools with all their might try to overcome this gapOften without extracting significant information from non -text content.
Multi -modal opportunities
Problems of processing complex documents developed with the introduction of multimodal capabilities in the foundation models. Commercial models and open source models can now now Process both text and visual contentThe field of this possibility of vision eliminates the need for individual work processes of operation of the text, offering an integrated approach to processing mixed PDF files.
Using these features of vision, Models can swallow entire pages at the same time, recognizing the structures of the layout, the tags of the diagrams and the content of the tableThis field not only reduces manual efforts, but also improves the scalability and quality of data, which makes it a powerful factor for RAG work processes, which rely on accurate information from various sources.
Report on the research of data recruitment management for data recruitment
To demonstrate the solution to the problem of manual evaluation, I checked my approach using the example of the document – the Cerulli report of 2023. This type of document is typical in asset management, where analysts’ reports often combine text with complex visual effectsA field for an assistant search with a rag of such a knowledge case will probably contain many such documents.
My goal was Demonstrate how to use a single document to create vapor of questions and answers, including both text and visual elementsThe field despite the fact that I did not determine the specific aspects for the vapor of questions and answers in this test, the implementation in the real world will include the provision of details about the types of questions (comparative, analysis, multiple choice), topics (investment strategies, types of accounts) And many other aspects. The main direction of this experiment was to ensure the creation of LLM, which included visual elements and gave reliable answers.

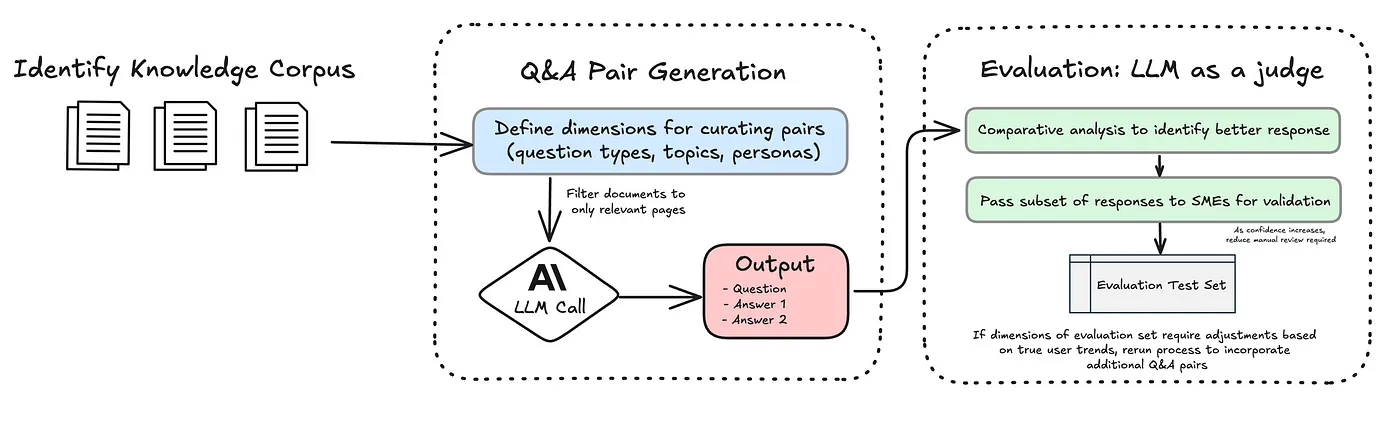
My workflow, illustrated in the diagram, uses the Claud Sonnet 3.5 model from Anpropic, which simplifies the process of working with PDF, processing the conversion of documents into images before transmitting them to the model. This Built -in functionality eliminates the need for additional third -party dependencies, optimization of the work process and reducing the complexity of the codeField
I excluded the preliminary pages of the report, such as the content and glossary, focusing on pages with appropriate content and diagrams to create pairs of questions and answers. Below is a hint that I used to create initial sets of questions and answers.
You are an expert at analyzing financial reports and generating question-answer pairs. For the provided PDF, the 2023 Cerulli report:1. Analyze pages {start_idx} to {end_idx} and for **each** of those 10 pages:
- Identify the **exact page title** as it appears on that page (e.g., "Exhibit 4.03 Core Market Databank, 2023").
- If the page includes a chart, graph, or diagram, create a question that references that visual element. Otherwise, create a question about the textual content.
- Generate two distinct answers to that question ("answer_1" and "answer_2"), both supported by the page’s content.
- Identify the correct page number as indicated in the bottom left corner of the page.
2. Return exactly 10 results as a valid JSON array (a list of dictionaries). Each dictionary should have the keys: “page” (int), “page_title” (str), “question” (str), “answer_1” (str), and “answer_2” (str). The page title typically includes the word "Exhibit" followed by a number.
Generation questions and answers
To clarify the process of generating questions and absorption, I introduced Comparative approach to learning This generates two different answers for each question. At the stage of assessment, these answers are evaluated by key measurements, such as accuracy and clarity, with a stronger answer selected as the final answer.
This approach reflects how it is often easier for people to make decisions when comparing alternatives, and does not evaluate something in isolation. This is similar to eye examination: the optometrist does not ask if your vision has improved, but instead represents two lenses and asks what is more clear, option 1 or option 2? This comparative process eliminates the ambiguity of evaluating absolute improvement and focuses on relative differencesMaking the choice simpler and more effective. In the same way, representing two specific answer options, the system can more effectively evaluate which answer is stronger.
This methodology is also called the best practice in the article “What we learned from the year of building with LLMS” leaders in the space of artificial intelligence. They highlight the value of paired comparisons, saying: “Instead of asking LLM to dial one conclusion on the Likert scale, imagine it with two options and ask him to choose the best. This leads to more stable results. I strongly recommend reading their series of three parts, as it gives invaluable information about the construction of effective systems with LLMS!
LLM rating
To evaluate the generated pairs of questions and answers, I used Claude Opus for its advanced arguments. Acts as “judge” LLM compared two answers generated for each question, and chose the best option based on criteria such as direct and clarity. This approach is confirmed by extensive studies (Zheng et al., 2023), which show LLMS, which can conduct estimates along with human reviewers.
This approach Significantly reduces the amount of manual review required by SMEProviding a more scale and effective clarification process. Although the SMEs remain necessary at the initial stages to verify questions and check the system outputs, this dependence is reduced over time. As soon as a sufficient level of reliability is established in the performance of the system, the need for frequent checks of points is reduced, which allows the SME to focus on tasks with a higher cost.
The lessons are learned
The possibility of PDF Claude has a limit of 100 pages, so I divided the initial document into four 50-page sections. When I tried to process every 50-page section in one request, and clearly indicated the model to generate one pair of questions and answers to the page, he still missed several pages. The limit of token was not a real problem; The model, as a rule, focused on what content he considered the most relevant, leaving certain pages unpromected.
To solve this, I experimented with the processing of a document in small batches, tested 5, 10 and 20 pages at a time. Thanks to these tests, I found that parties of 10 pages (for example, pages 1–10, 11–20, etc.) provide the best balance between accuracy and efficiency. Processing 10 pages per party provided constant results on all pages when optimizing performance.
Another problem was to connect the pairs of questions and answers back to their source. The use of tiny page numbers in the lower PDF cake did not work. On the contrary, pages or clear headings in the upper part of each page served as reliable anchors. The model was easier to raise and helped me to accurately display every couple of questions and answers to the correct section.
An example of a conclusion
Below is an approximate page from a report with two tables with numerical data. The following question was generated for this page:
How has the AUM distribution in RIA hybrid firms changed?

Reply: Medium -sized firms (from 25 to <100 million dollars) experienced a decrease in AUM from 2.3% to 1.0%.
The first table in the 2017 column shows 2.3% AUM for medium -sized firms, which decreases to 1.0% in 2022, thereby demonstrating the ability of LLM to synthesize visual and tabular content.
Advantages
The combination of caching, party and sophisticated work process of questions and answers led to three key advantages:
Caching
- In my experiment, processing a single report without caching would cost $ 9, but using caching, I reduced this cost to $ 3 – 3x cost savingsThe field according to the APROPIC pricing model, the creation of the cache costs $ 3.75 / a million tokens, however, is read from the cache, is only 0.30 USA / million tokens. On the contrary, input tokens are tokens in the amount of $ 3 / million, when caching is not used.
- In a real scenario with more than one document, savings become even more significant. For example, the processing of 10,000 research reports on a similar length without caching will cost $ 90,000 in the form of input costs. With caching, this cost is reduced to $ 30,000, reaching the same accuracy and quality when saving 60,000 dollarsField
Discounted batch processing
- Using API API API API reduces output costs, which makes it much cheaper for certain tasks. As soon as I confirmed the tips, I launched one partial task to evaluate all the sets of answers and answers at once. This method turned out to be much more profitable than processing each pair of questions and answers separately.
- For example, Claude 3 Opus usually costs $ 15 per million tokens. Using the party, this is reduced to $ 7.50 per million tokens – Reduction by 50%A field in my experiment, each pair of questions and answers generated an average of 100 tokens, which led to the fact that about 20,000 tokens leads to the document. At the standard rate, it would cost $ 0.30. When processing the party, the cost was reduced to $ 0.15.
Time saved for SMEs
- Thanks to the more accurate, rich contexts, a pair of questions and answers, experts on objects of objects spent less time, sifting PDF files and explaining the details, as well as more time to focus on a strategic sense. This approach also eliminates the need to hire additional personnel or distribute internal resources for manual data sets, a process that can be laborious and expensive. By automating these tasks, companies will significantly save labor costs when optimizing the workflow of SMEs, which makes this a scalable and economically effective solution.
Source link